边缘运算服务器 - 「效能」为决胜点
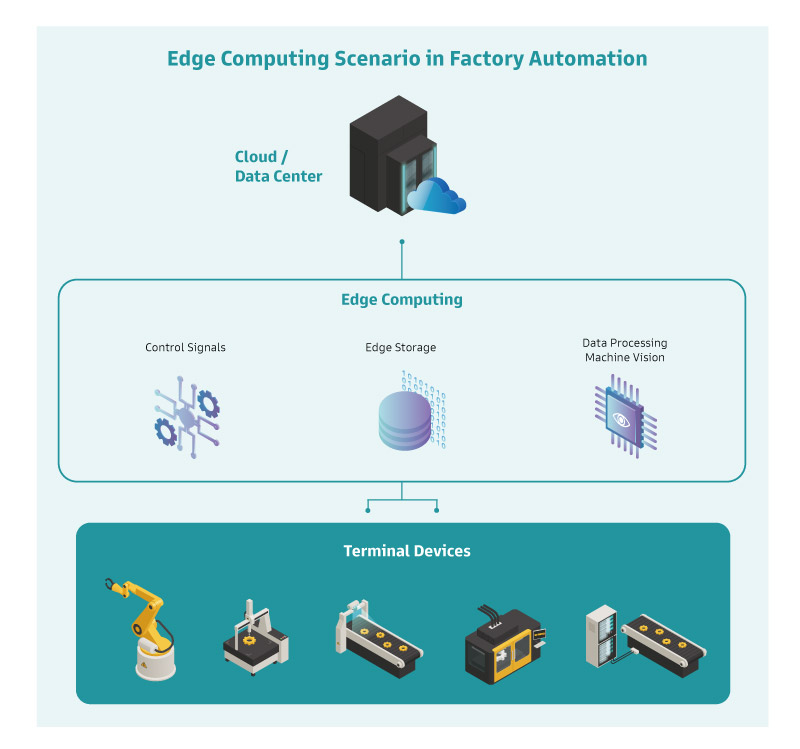
边缘运算服务器需具备微型数据中心及边缘云的能耐,不脱处理速度、传输速度与储存效率。运算着重实时与精准,传输必须低延迟,而在数据的存取上得有足够的带宽与空间,这些都刚好是服务器等级主板的特长。
以 DFI ICX610-C621A-C621A 为例, 结合多核心多线程的第三代 Intel® Xeon® 处理器为多任务好手,能满足来自多台终端设备的数据处理需求,数量惊人的内外部传输埠口也提供了充裕的传输通道,同时可管理为数众多的储存装置,这些边缘服务器的功能在此张主板上全都能一次达成。
ICX610-C621A-C621A 专为 Intel® Ice Lake 平台量身打造, 支持第三代 Intel® Xeon® 处理器。此代 Xeon® 处理器于 AI 的运算能力极为突出,包含以下三方面的提升:
-
Intel® Deep Learning Boost
-
Intel® AVX-512
-
支援PCIe 4.0
Intel® Deep Learning Boost 搭配 Intel® AVX-512
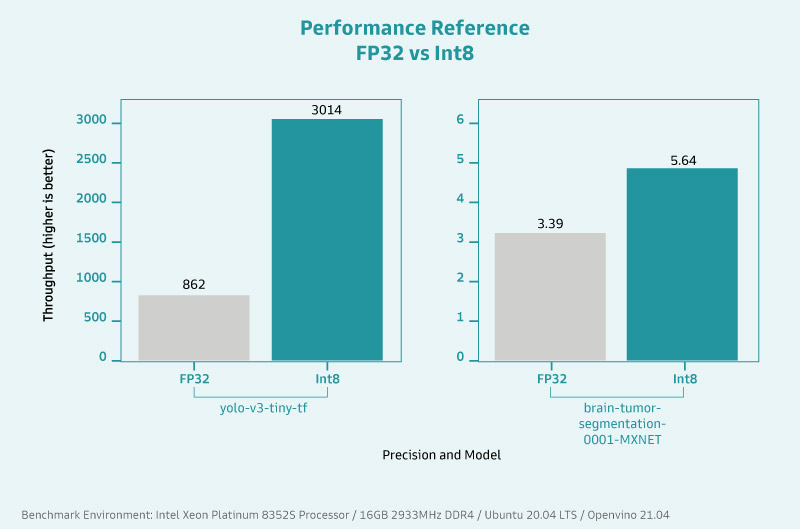
Intel®Deep Learning Boost 并非于此代 Xeon® 处理器才问世,但这个立基于 Intel® AVX512 VNNI 指令集的技术随着处理器的更新而益发强劲,在深度学习及视觉分析效能方面都有显著提升。在 AI 应用的训练阶段,效能便获得60% 的提升,而在实际进行推论时,也比××代快 30 倍以上。
用更严谨的数据来判断及解析,VNNI 暴增了低精度运算在 AI 深度学习及推论的效能成长。透过低精度运算的优化,在进行 AI 应用时处理器的资料吞吐量大幅增加,平均可创造约 2.19 倍的差距,这意味着在时间上快了约 45%。
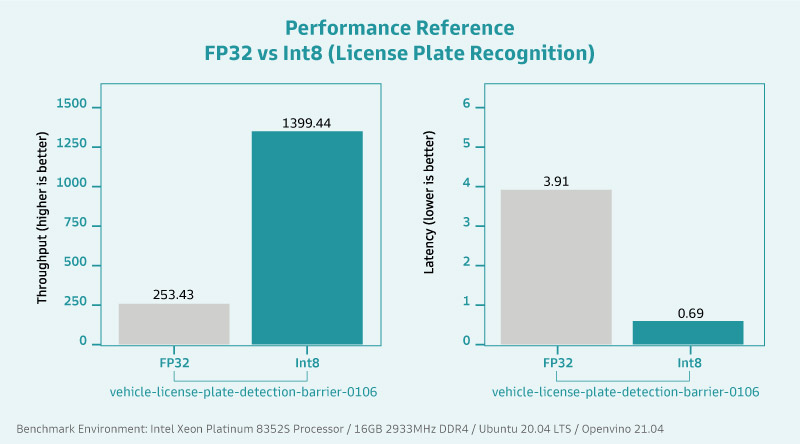
45% 的速度提升代表什么?试想在产在线原本辨识一处产品缺陷的耗时为 25 毫秒(注 1),节省了近一半的时间后会小于 15 毫秒,积沙成塔下,同样的时间内能辨识的产品数量就会变多,大量布署下能节省的工时及产力提升更是不言而谕。
而在医疗应用上,辨识速度的提升对于受检者而言,亦可大幅降低容易造成不适的生理扫描或幅射曝露时间,提供更优质的检测体验。